A quick-start guide to PBjam¶
Using the session class¶
PBjam is meant to be an easy to use, but also flexible, code for measuring the individual frequencies of solar-like oscillators. This process is broadly speaking broken down into two parts, the mode identification and the peakbagging steps. The session class is a top-level wrapper and is meant to handle the full peakbagging process for the most part using the default settings in PBjam.
In this tutorial we will just show you how to quickly start peakbagging your favorite stars using the session class. For a detailed description of how PBjam does all this, see the Advanced guide.
So lets do some peakbagging already!¶
Ok then! Let’s start by initializing the session class, using a target ID and some physical parameters. We’ll also add a path to store the output and ask PBjam to make some plots for us.
[1]:
import pbjam as pb
sess = pb.session(ID='KIC4448777',
numax=(220.0, 3.0),
dnu=(16.97, 0.05),
teff=(4750, 250),
bp_rp=(1.34, 0.1),
exptime=1800,
path = '.')
2021-05-05, 06:29:18 - theano.tensor.blas: Using NumPy C-API based implementation for BLAS functions.
2021-05-05, 06:29:18 - theano.tensor.blas: Using NumPy C-API based implementation for BLAS functions.
We then call the class instance to begin the actual peakbagging, here using 7 radial orders.
Warning: The next step might take several minutes to run
[2]:
sess(norders = 7, make_plots=True);
Starting KDE estimation
/home/nielsemb/work/repos/PBjam/pbjam/priors.py:153: UserWarning: Only 61 star(s) near provided numax. Trying to expand the range to include ~100 stars.
f'Trying to expand the range to include ~{KDEsize} stars.')
Steps taken: 2000
Steps taken: 3000
Steps taken: 4000
Steps taken: 5000
Chains reached stationary state after 5000 iterations.
2021-05-05, 06:31:00 - matplotlib.legend: No handles with labels found to put in legend.
2021-05-05, 06:31:00 - matplotlib.legend: No handles with labels found to put in legend.
Starting asymptotic peakbagging
Steps taken: 2000
Chains reached stationary state after 2000 iterations.
Starting peakbagging
/home/nielsemb/work/repos/PBjam/pbjam/peakbag.py:400: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
progressbar=False)
2021-05-05, 06:35:26 - pymc3 : Auto-assigning NUTS sampler...
2021-05-05, 06:35:26 - pymc3 : Initializing NUTS using adapt_diag...
2021-05-05, 06:35:31 - pymc3 : Sequential sampling (2 chains in 1 job)
2021-05-05, 06:35:31 - pymc3 : NUTS: [back, height2, height0, l2, l0, width2, width0]
2021-05-05, 06:37:41 - pymc3 : Sampling 2 chains for 1_500 tune and 1_000 draw iterations (3_000 + 2_000 draws total) took 129 seconds.
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
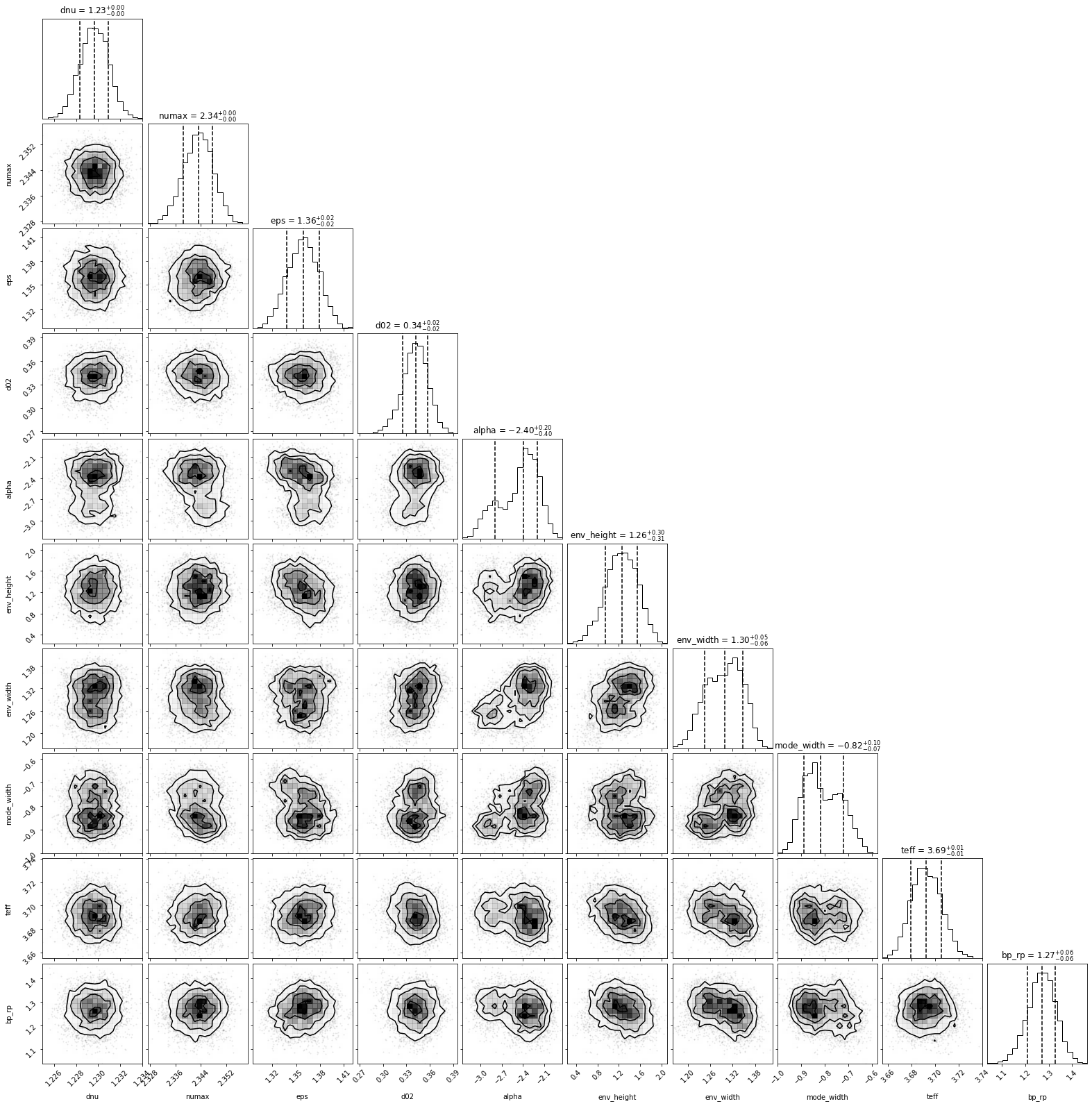
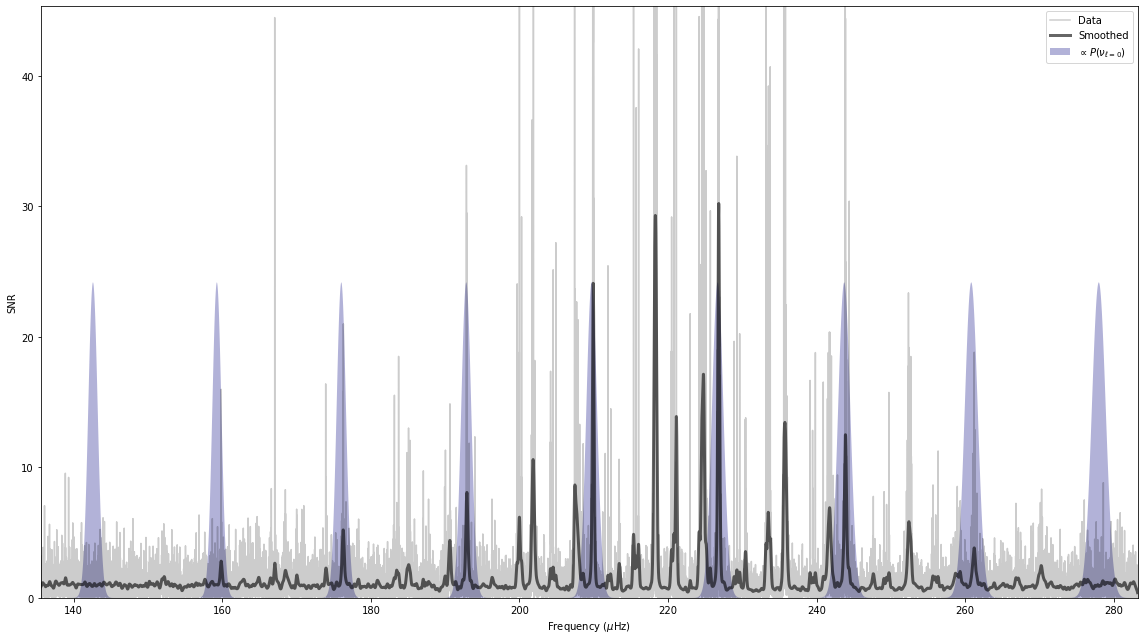
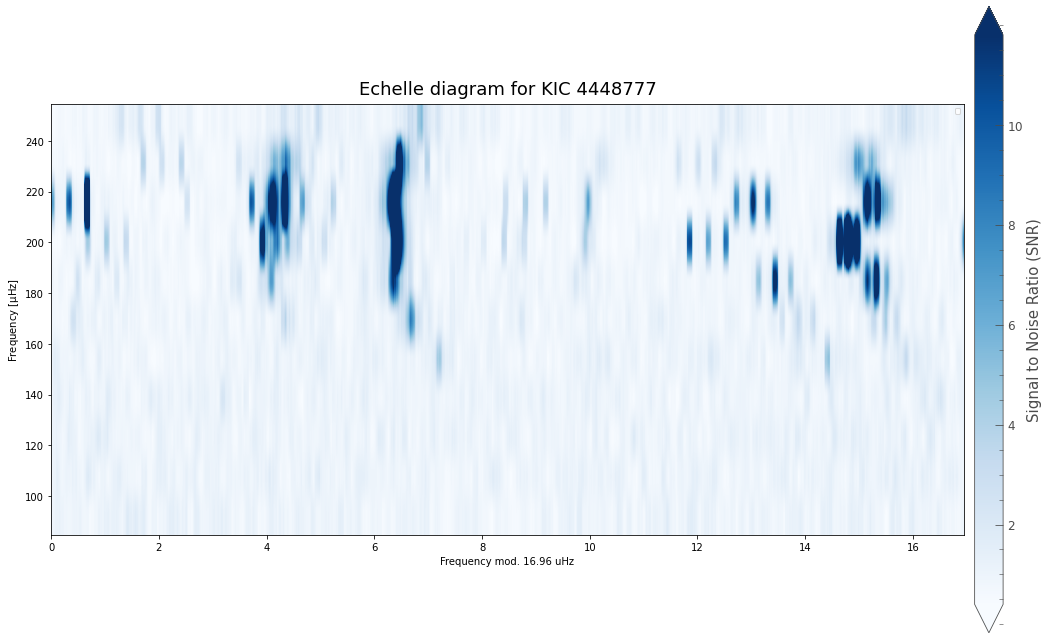
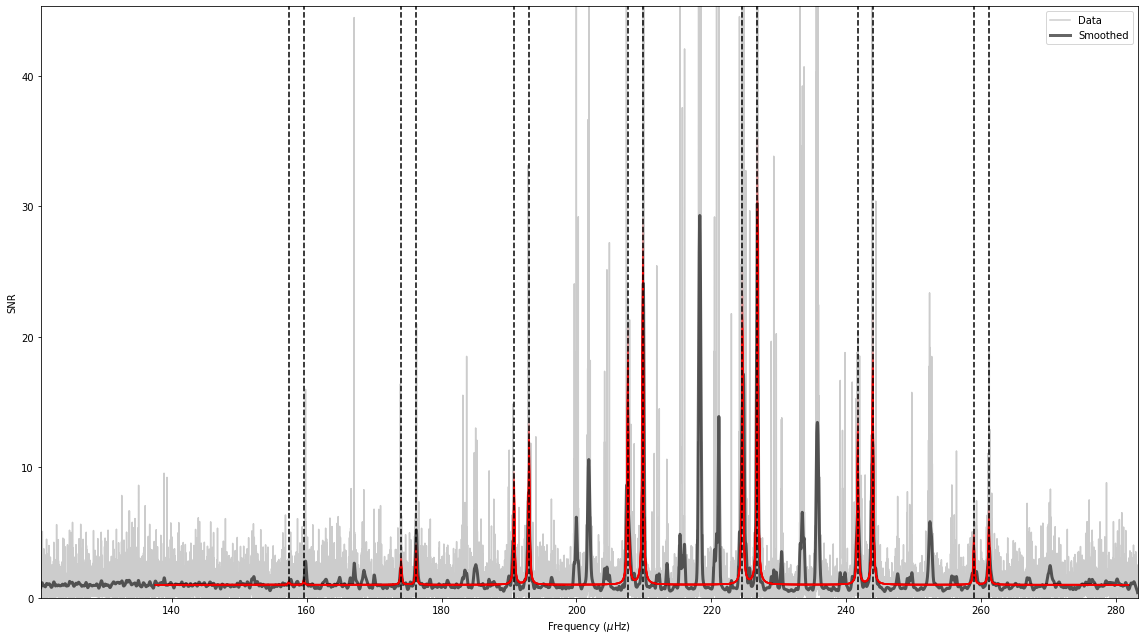

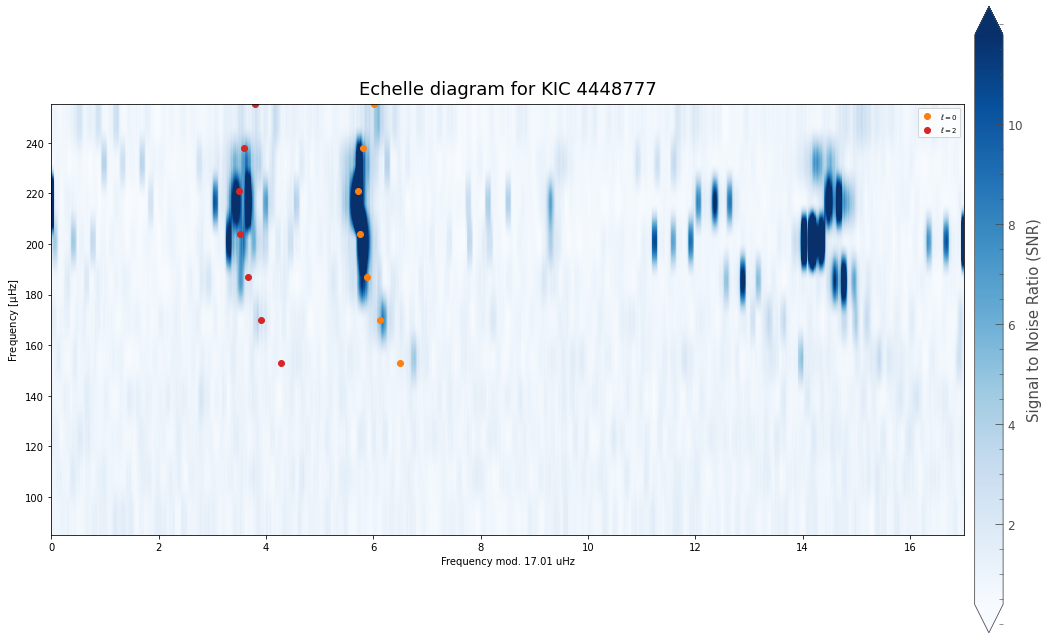
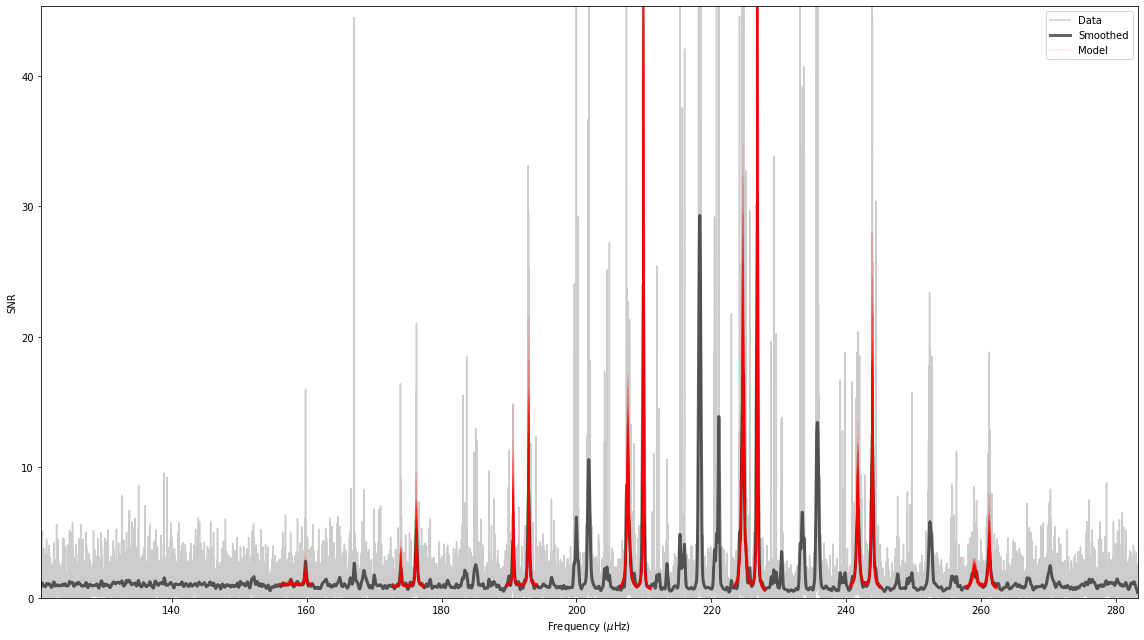
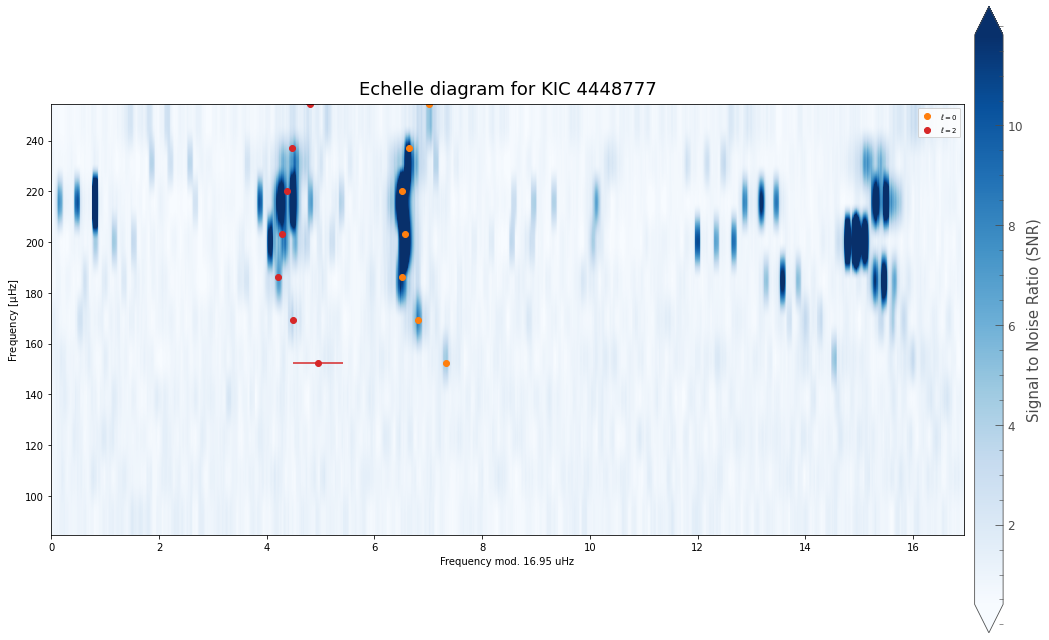
And that’s it!
What’s actually going on here?¶
To peakbag a star PBjam needs relatively few input values. In the simplest case it just needs the name of the target, to look up the lightcurve on the MAST server using LightKurve, and a few physical parameters: - The frequency of maximum oscillation power (\(\nu_{max}\)), - the large frequency separation (\(\Delta \nu\)), - the effective surface temperature (\(T_{\mathrm{eff}}\)), - the Gaia \(B_p-R_p\) color, - and the error estimates of the above.
Some of these parameters may not be necessary in future versions, as they can and should be infered from the timeseries and others can be looked up online, but for now PBjam isn’t smart enough to do that for you.
Based on these inputs alone, PBjam will: 1. Download the light curve from MAST, 2. Perform the mode ID by fitting the asymptotic relation to the power spectrum, using a KDE of previous values from Kepler as a prior. Here the sampling is done using using emcee. 3. Perform the peakbagging using the pymc3 Hamiltonian Monte Carlo (HMC) sampler, but without the to many priors. 4. Output the results for each star in a separate directory
Peakbagging multiple stars¶
The session class can easily handle multiple targets. This can be done by providing lists of the above input values for each of the stars you want to peakbag:
[3]:
multi_sess = pb.session(ID=['KIC4448777', 'KIC2307683'],
numax=[(220.0, 3.0), (39.95, 0.51)],
dnu=[(16.97, 0.05), (4.31, 0.01)],
teff=[(4750, 250), (4799, 100)],
bp_rp=[(1.34, 0.1), (1.37, 0.01)],
exptime=[1800, 1800],
path = '.')
Peakbagging many stars from a csv¶
Alternatively you can also just throw everything into a csv file.
[4]:
sess = pb.session(dictlike='mytgts.csv')
Here you can either just give PBjam the path to the csv file, or load the csv manually as a pandas dataframe or Python dictionary.
Note: You must have a specific set of keywords in the dictionary/dataframe/csv file, shown below
[5]:
import pandas as pd
df = pd.read_csv('mytgts.csv')
df.head()
[5]:
| ID | dnu | dnu_err | numax | numax_err | teff | teff_err | bp_rp | bp_rp_err | exptime | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KIC1433593 | 6.241 | 0.013 | 69.14 | 0.59 | 4956 | 100 | 1.327025 | 0.05 | 1800 |
| 1 | KIC1433730 | 4.085 | 0.019 | 40.37 | 0.54 | 4767 | 100 | 1.424954 | 0.05 | 1800 |
| 2 | KIC2018392 | 3.795 | 0.013 | 33.92 | 0.55 | 4908 | 100 | 1.417112 | 0.05 | 1800 |
| 3 | KIC2140446 | 5.673 | 0.012 | 57.60 | 0.56 | 4665 | 100 | 1.446697 | 0.05 | 1800 |
| 4 | KIC2307683 | 4.309 | 0.012 | 39.95 | 0.51 | 4799 | 100 | 1.369279 | 0.05 | 1800 |
Peakbagging even more stars¶
If you wish to peakbag even more stars, as in a lot of stars (>10000) we recommend you prepare the relevant data manually and then add the filenames to a timeseries or psd column in the csv file. These should be in two-column ascii format with no header or commented by #. Both may be added, but in that case PBjam will default to using the psd column.
Output from PBjam¶
By default the output will be stored in the current working directory, but this can of course be changed. PBjam will create a directory for each star that is analyzed, where the diagnostics plots and output tables will be stored.
The results of the fit are output as a csv file, containing all the fit parameters of the peakbagging fit.
[6]:
output = pd.read_csv('peakbag_summary_KIC4448777.csv')
output.head()
[6]:
| name | mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | l0[0] | 159.839 | 0.030 | 159.780 | 159.892 | 0.001 | 0.001 | 1654.0 | 981.0 | 1.0 |
| 1 | l0[1] | 176.269 | 0.019 | 176.239 | 176.306 | 0.000 | 0.000 | 3171.0 | 1105.0 | 1.0 |
| 2 | l0[2] | 192.921 | 0.015 | 192.892 | 192.947 | 0.000 | 0.000 | 2825.0 | 1395.0 | 1.0 |
| 3 | l0[3] | 209.924 | 0.009 | 209.907 | 209.941 | 0.000 | 0.000 | 2936.0 | 1150.0 | 1.0 |
| 4 | l0[4] | 226.818 | 0.009 | 226.800 | 226.836 | 0.000 | 0.000 | 3113.0 | 1320.0 | 1.0 |
Would you like to know more?¶
Read the API for the session class and check out the other tutorials.