Using the star class¶
This is a tutorial for using the star class.
Like the session class, the star class is a wrapper for much of the functionality in PBjam. The session class actually just creates a list of star class instances and loops over this list during the peakbagging process.
The star class is useful if you want a bit more control over, e.g., the light curve reduction and power spectrum computation, but otherwise we recommend using the session class.
Preparing the data¶
The star class takes lightkurve.periodogram objects as data input, while the remaining parameters are identical to those for session, although lists are not allowed here since a star class instance only refers to a single target.
Let’s create a Lightkurve lightcurve object and then compute the periodogram.
[1]:
import lightkurve as lk
import pbjam as pb
print(f'Lightkurve version {lk.__version__}')
print(f'PBjam version {pb.__version__}')
2021-05-05, 06:46:08 - theano.tensor.blas: Using NumPy C-API based implementation for BLAS functions.
2021-05-05, 06:46:08 - theano.tensor.blas: Using NumPy C-API based implementation for BLAS functions.
Lightkurve version 2.0.9
PBjam version 1.0.1
While the PDCSAP pipeline does a pretty good job in preparing light curves for asteroseismology, we might want to perform some manipulation of the data. Since we’re using Lightkurve, for the purposes of this exercise we’ll just use some of the built-in functions.
[2]:
lcs = lk.search_lightcurve('KIC4448777', exptime=1800, mission='Kepler').download_all()
lc = lcs.stitch().normalize().flatten(window_length=401).remove_outliers(4)
/home/nielsemb/.local/lib/python3.7/site-packages/lightkurve/lightcurve.py:995: LightkurveWarning: The light curve already appears to be in relative units; `normalize()` will convert the light curve into relative units for a second time, which is probably not what you want.
LightkurveWarning,
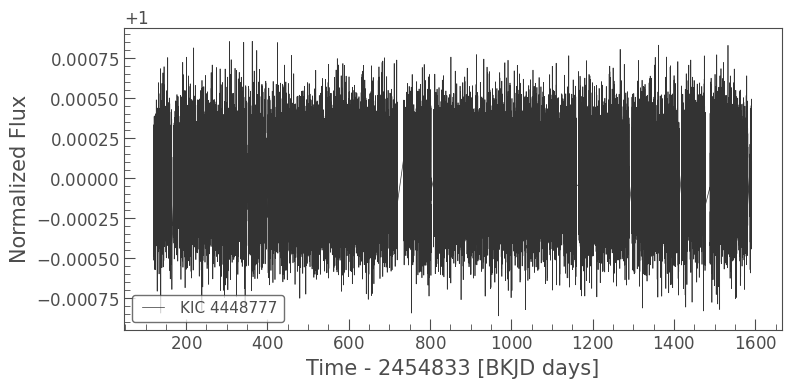
We can have a quick look at the time series to check that everything looks good
[3]:
lc.plot()
[3]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fd275e30210>
Now lets compute the power density spectrum
[4]:
pg = lc.to_periodogram(normalization='psd', minimum_frequency=150.0)
The functions in PBjam work best if you are using the SNR spectrum. That is, the powerspectrum with the background noise level divided out. Again, this can be done manually, but Lightkurve has a built-in function for this too, so for the purposes of this tutorial we’ll just use that.
[5]:
pg = pg.flatten()
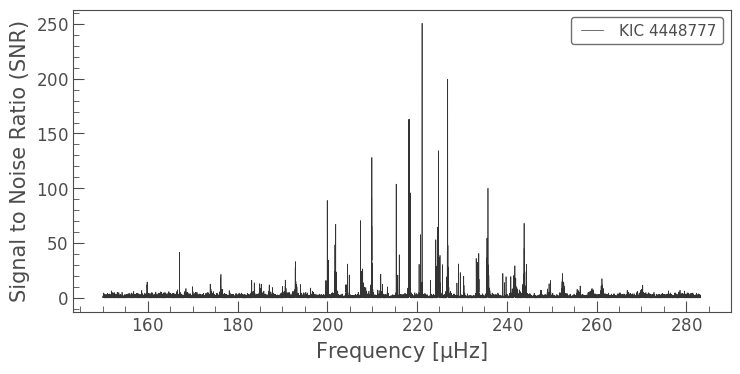
Again, lets just have a quick look to make sure the power spectrum looks good
[6]:
pg.plot()
[6]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fd275a191d0>
Alright, time to peakbag¶
We’ll start by defining some of the physical parameters of the star we’re looking at, in this case we downloaded the lightcurve for KIC4448777.
Note: When calling the star class here we don’t actually have to use the KIC identifier as the ID, we can pick any name we want. Only session needs a proper identifier, since it uses Lightkurve.search_lightcurvefile.
[7]:
ID = 'catname'
numax = (220.0, 3.0)
dnu = (16.97, 0.05)
teff = (4750, 100)
bp_rp = (1.34, 0.1)
Now that we have a power spectrum and some input parameters we can initialize the star class instance.
[8]:
st = pb.star(ID, pg, numax, dnu, teff, bp_rp)
Like session, the star class has a ‘do-it-all’ functionality, which can be used by calling the class instance:
[9]:
st(norders = 7, make_plots=True)
Starting KDE estimation
/home/nielsemb/work/repos/PBjam/pbjam/priors.py:153: UserWarning: Only 61 star(s) near provided numax. Trying to expand the range to include ~100 stars.
f'Trying to expand the range to include ~{KDEsize} stars.')
Steps taken: 2000
Steps taken: 3000
Steps taken: 4000
Steps taken: 5000
Chains reached stationary state after 5000 iterations.
2021-05-05, 06:47:57 - matplotlib.legend: No handles with labels found to put in legend.
Starting asymptotic peakbagging
Steps taken: 2000
Chains reached stationary state after 2000 iterations.
Starting peakbagging
/home/nielsemb/work/repos/PBjam/pbjam/peakbag.py:400: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
progressbar=False)
2021-05-05, 06:52:13 - pymc3 : Auto-assigning NUTS sampler...
2021-05-05, 06:52:13 - pymc3 : Initializing NUTS using adapt_diag...
2021-05-05, 06:52:18 - pymc3 : Sequential sampling (2 chains in 1 job)
2021-05-05, 06:52:18 - pymc3 : NUTS: [back, height2, height0, l2, l0, width2, width0]
2021-05-05, 06:54:06 - pymc3 : Sampling 2 chains for 1_500 tune and 1_000 draw iterations (3_000 + 2_000 draws total) took 108 seconds.
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,

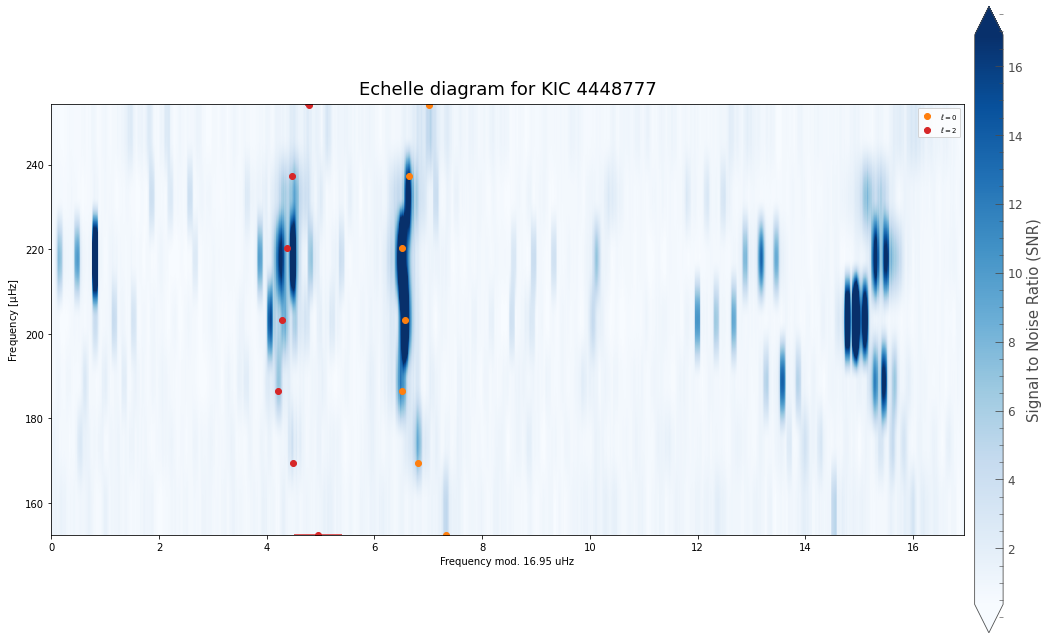
A bit more step-by-step¶
In the following we’ll show the different steps that PBjam takes when you ask it to ‘do-it-all’. It’s not a fully detailed explanation, with theory and everything, but should give you a bit more of a feel for the way PBjam is set up. For even more details, see the Advanced notebook.
The first step that PBjam takes is to construct a prior and determine the most likely starting locaiton for a spectrum model using the p-mode asymptotic relation.
PBjam does first computing a Kernel Density (KDE) estimate based on large sample of previous fits to other stars. This encodes the knowledge of the covariance of these parameters, for a wide range of stars. Given a set of input parameters \(\nu_{max}\), \(\Delta \nu\), \(T_{\mathrm{eff}}\), \(B_p-R_p\), this prior KDE is then sampled to find the most likely starting location.
This is done calling the star.run_kde function.
[10]:
st = pb.star(ID, pg, numax, dnu, teff, bp_rp, path = '.')
st.run_kde()
Starting KDE estimation
/home/nielsemb/work/repos/PBjam/pbjam/priors.py:153: UserWarning: Only 61 star(s) near provided numax. Trying to expand the range to include ~100 stars.
f'Trying to expand the range to include ~{KDEsize} stars.')
Steps taken: 2000
Steps taken: 3000
Steps taken: 4000
Steps taken: 5000
Steps taken: 6000
Steps taken: 7000
Chains reached stationary state after 7000 iterations.
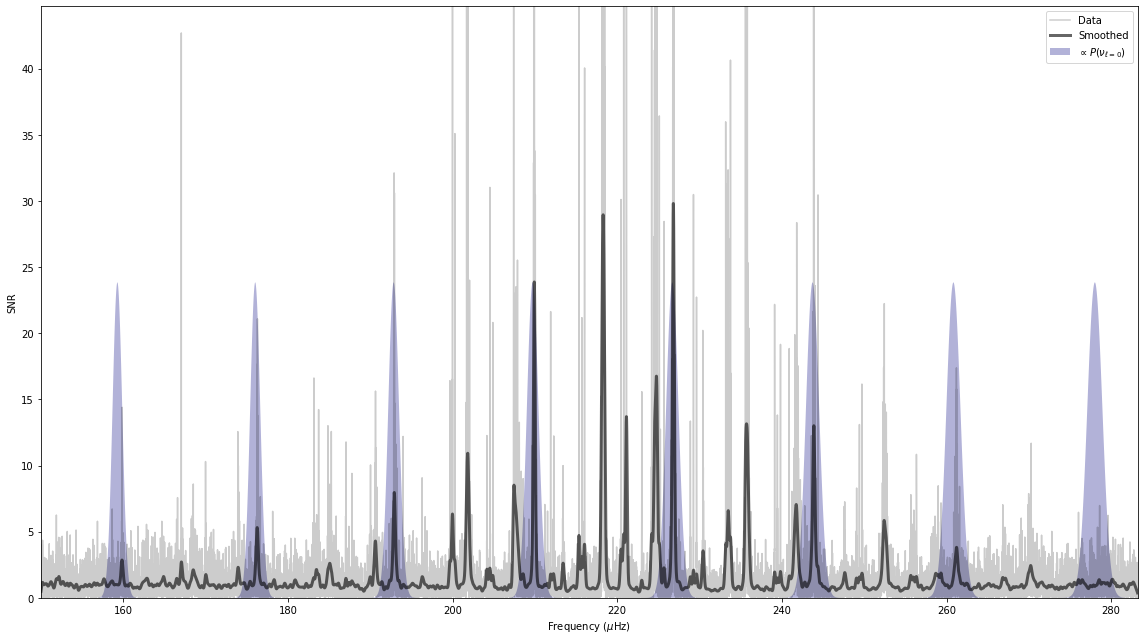
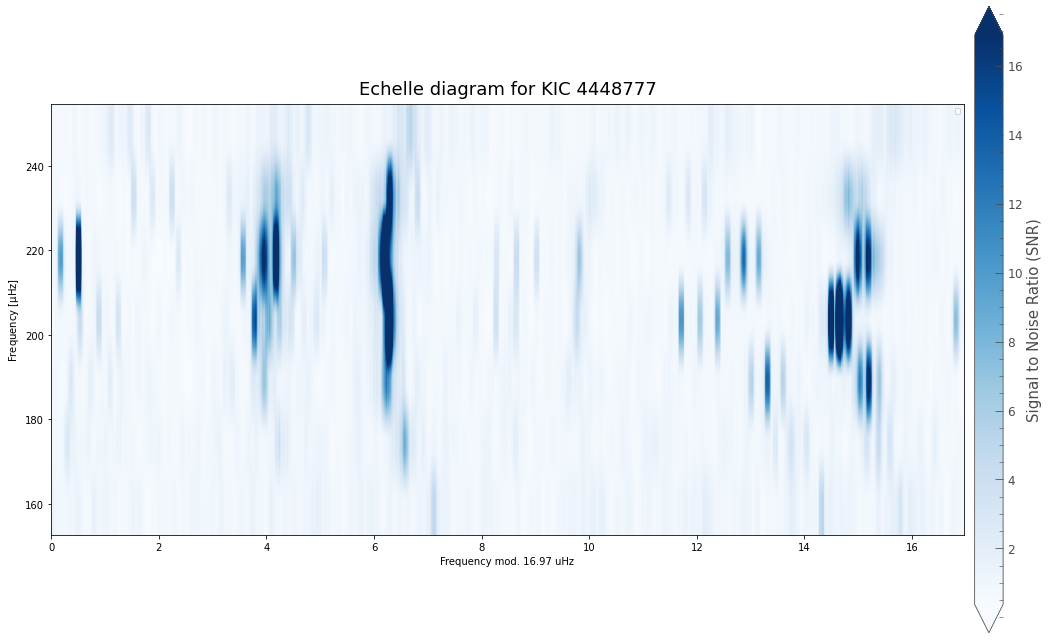
The way we can evaluate the \(\epsilon\) value that PBjam finds, is to plot where it thinks the \(l=0\) modes are likely to be.
[11]:
st.kde.plot_spectrum(pg);
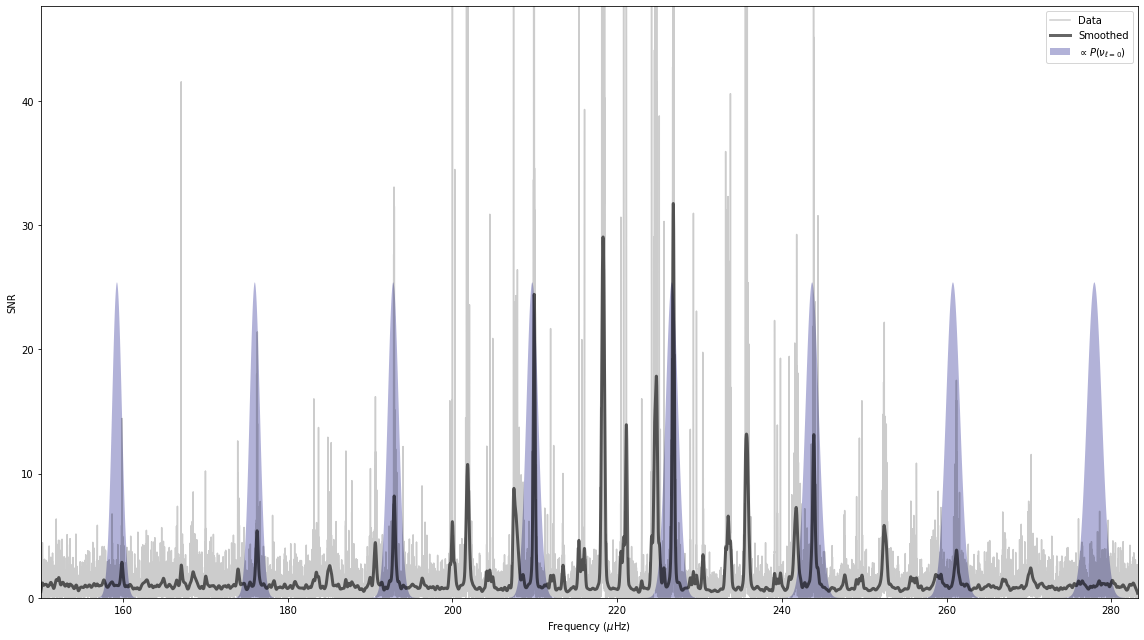
The purple distributions indicate where PBjam thinks the \(l=0\) modes are. At this point PBjam hasn’t actually evaluated the power spectrum yet, it’s only working based on the physical parameters and prior information we have given it. The result looks pretty good.
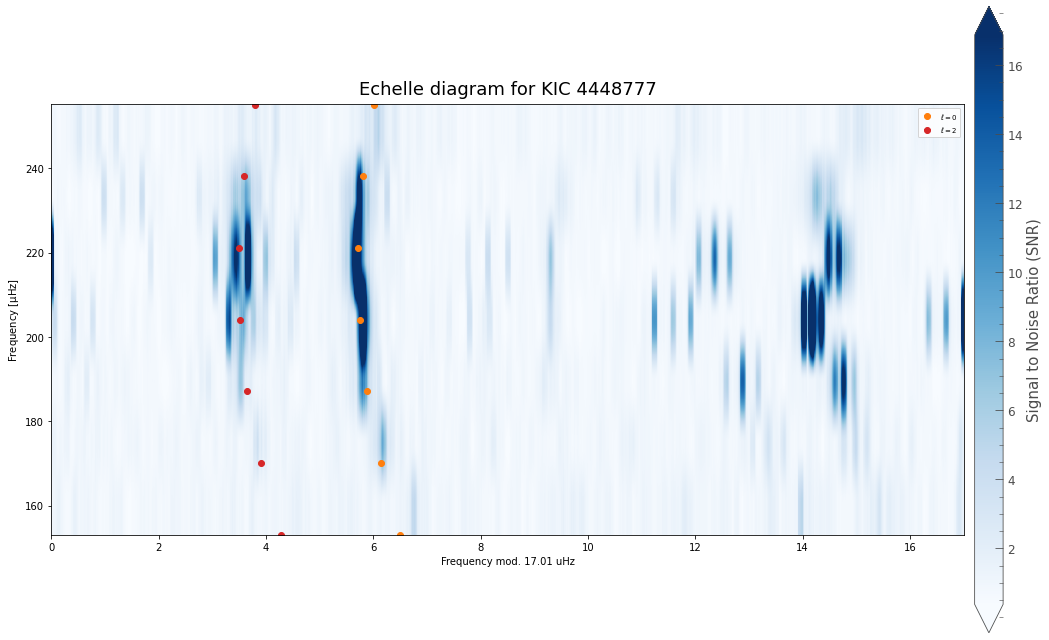
The next step is to fit an asymptotic relation to the data, using the KDE as a prior. In this case we do this using the asy_peakbag module, by calling star.run_asy_peakbag
[12]:
st.run_asy_peakbag(norders=7)
Starting asymptotic peakbagging
Steps taken: 2000
Chains reached stationary state after 2000 iterations.
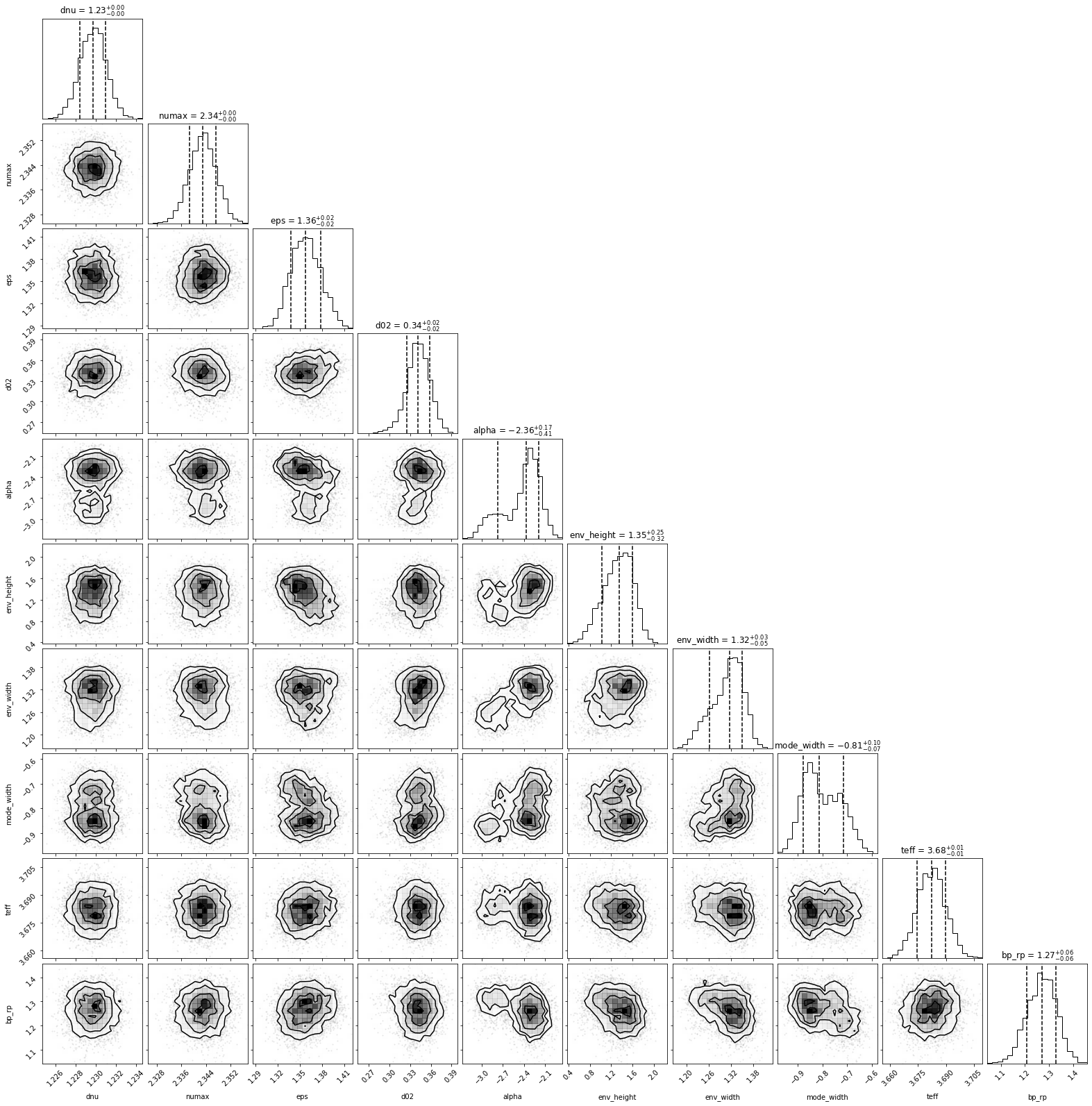
The result can be examined using a corner plot:
[13]:
st.asy_fit.plot_corner();

This plot shows all the parameters that asy_peakbag uses. The main parameters of interest are \(\nu_{max}\), \(\Delta \nu\), and \(\epsilon\). The remaining are less important, but may provide clues if something goes wrong during the fit.
Note The \(T_{\mathrm{eff}}\) and \(B_p-R_p\) might differ slightly from the initial guesses. In this case the true value of \(B_p-R_p\) is 1.23 (Gaia Collaboration et al. 2018).
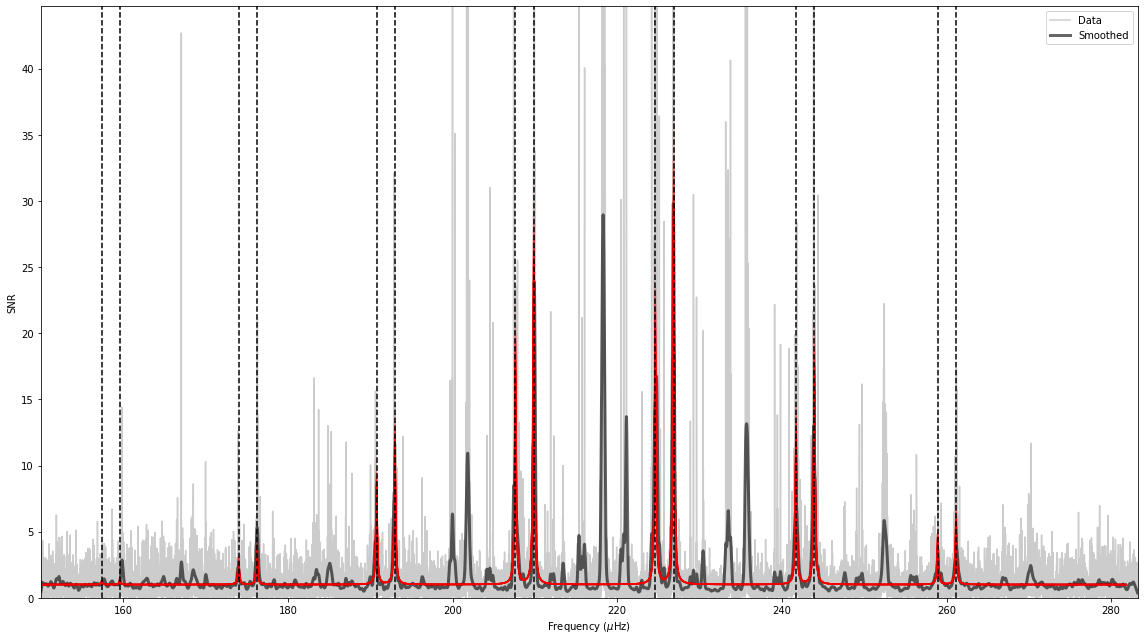
We can plot a sub-set of the best-fitting models on top of the spectrum:
[14]:
st.asy_fit.plot_spectrum();
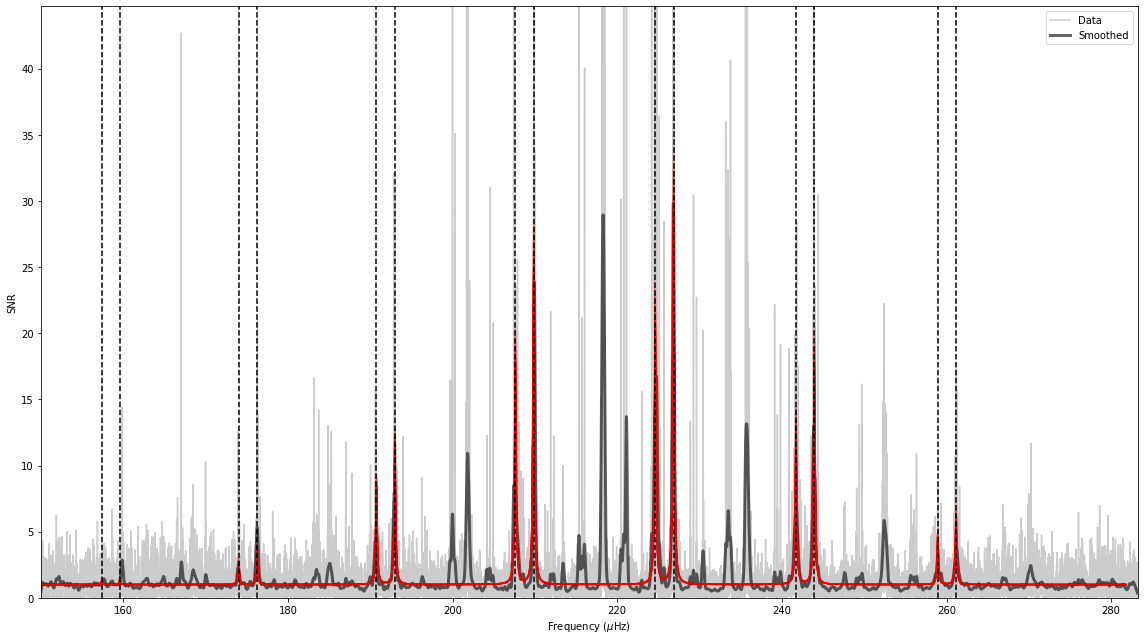
Now we have a bit better view of what the initial guess for the last peakbagging step will be, and you can see it already looks pretty good. To first order, asy_peakbag is probably good enough to get a reasonable estimate of the mode frequencies. However, second order effects like acoustic glitches are not currently incorporated into asy_peakbag. Furthermore, the above result is also strongly influenced by the prior, and the height ratio between the \(l=2\) and \(l=0\) which is fixed to \(0.7\).
This is why we have the final peakbagging step, where we allow the mode frequencies to move freely and using less informative priors on the mode heights and widths.
[15]:
st.run_peakbag()
Starting peakbagging
/home/nielsemb/work/repos/PBjam/pbjam/peakbag.py:400: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
progressbar=False)
2021-05-05, 07:00:40 - pymc3 : Auto-assigning NUTS sampler...
2021-05-05, 07:00:40 - pymc3 : Initializing NUTS using adapt_diag...
2021-05-05, 07:00:45 - pymc3 : Sequential sampling (2 chains in 1 job)
2021-05-05, 07:00:45 - pymc3 : NUTS: [back, height2, height0, l2, l0, width2, width0]
2021-05-05, 07:02:53 - pymc3 : Sampling 2 chains for 1_500 tune and 1_000 draw iterations (3_000 + 2_000 draws total) took 128 seconds.
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
/home/nielsemb/.local/lib/python3.7/site-packages/arviz/data/io_pymc3.py:100: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
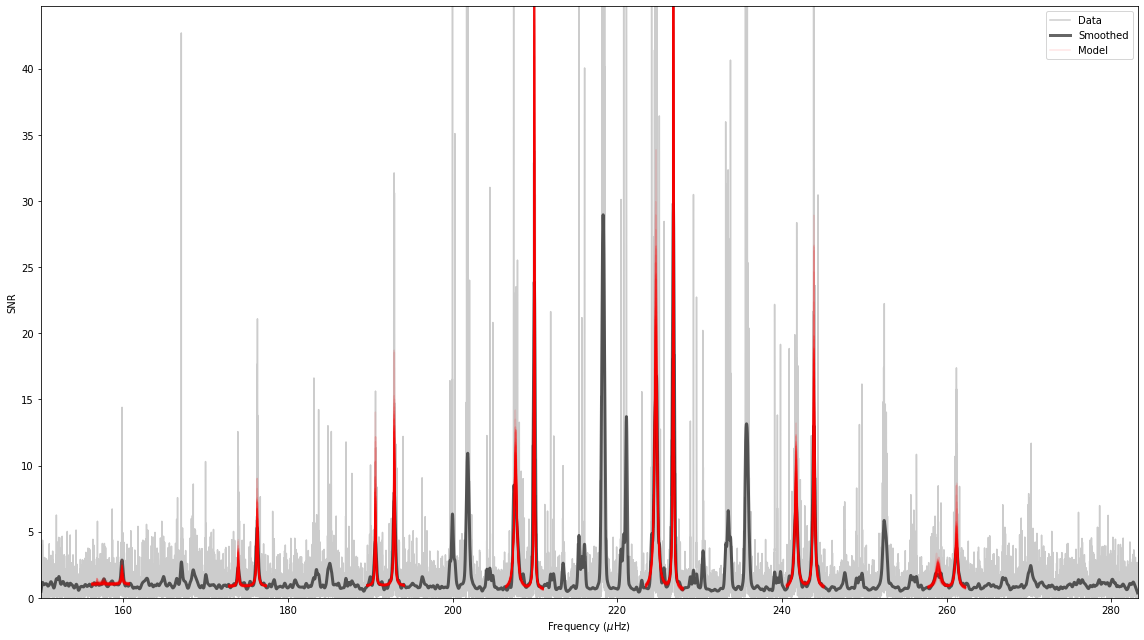
The result can be shown using the plot_spectrum method
[16]:
st.peakbag.plot_spectrum();
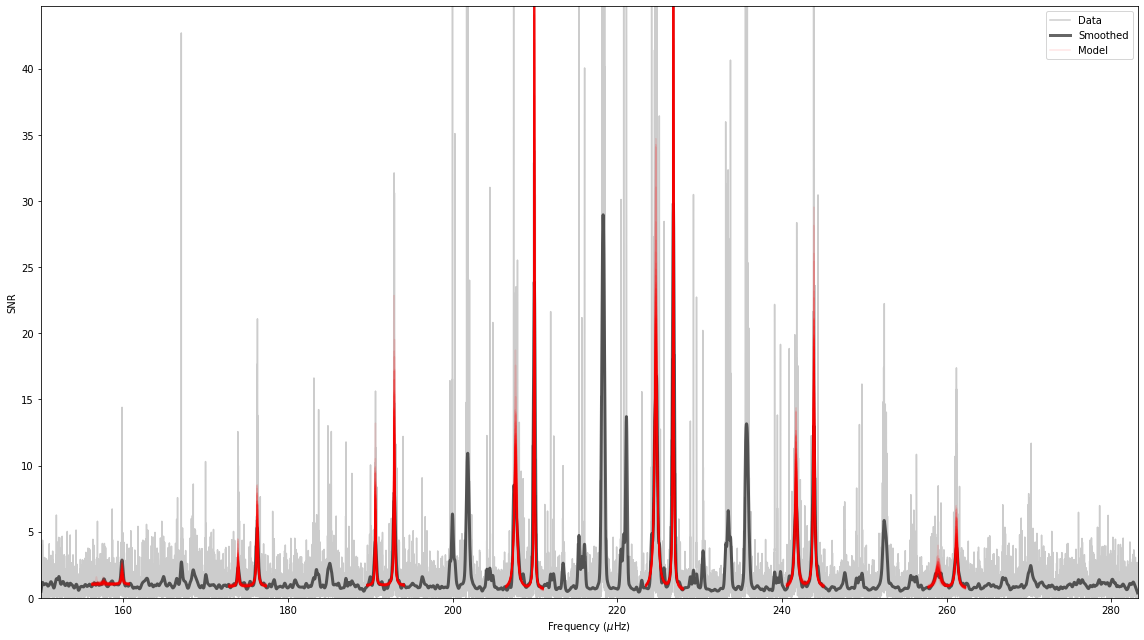
The sample of models drawn from the posterior all appear to agree on where the modes are and their amplitudes seem to be reasonable. The resulting summary dataframe from pymc3.stats.summary is written to the fit directory.
Would you like to know more?¶
Read the API for the star class and check out the other tutorials.